Искусственный интеллект пожирает сам себя, и никто его не останавливает.
526 цитирований. Ни одно решение не внедрено в масштабах. Внутри исследований, которые пугают лаборатории ИИ.
19 минут чтения · 11 февраля 2026 г. Деланоэ Пирард

Девять зеркал. Девять поколений. Каждое отражение теряет то, что делало оригинал уникальным. К девятому остается только шум. Это коллапс модели.
Телефонная игра Фредерика Бартлетта
В 1932 году британский психолог Фредерик Бартлетт провел эксперимент, который впоследствии стал легендарным. Он попросил группу участников прочитать индейскую народную сказку «Война призраков», а затем пересказать ее по памяти другому человеку, который, в свою очередь, пересказывал ее, и так далее.
К седьмому воспроизведению история стала неузнаваемой. Духи и каноэ исчезли. Элементы, чуждые культуре британских участников, были заменены безликими обобщениями. Рассказ был «нормализован», лишен всего, что делало его уникальным.
Бартлетт назвал этот метод последовательным воспроизведением . Суть в том, что каждое звено цепочки сохраняет то, что кажется знакомым, и отбрасывает остальное. Редкая информация исчезает первой.
В 2024 году группа исследователей из Кембриджа, Торонто и Оксфорда опубликовала в журнале Nature тревожное открытие : модели искусственного интеллекта делают то же самое ( Шумайлов и др., Nature 2024 ). Они назвали это коллапсом модели : прогрессирующей, необратимой деградацией моделей ИИ, обученных на синтетических данных. Только ИИ делает это сам с собой. И это происходит со всем интернетом.
Параллели поразительны. Но разница в масштабах ошеломляет. У Бартлетта было 10 участников и народная сказка. У нас миллиарды веб-страниц, сотни генеративных моделей и экосистема данных, где никто уже не знает, кто что написал.
Ирония очевидна: самые мощные машины, когда-либо созданные для генерации языка, уничтожают тот самый исходный материал, который необходим им для функционирования.
Вкратце:
0,1% синтетических данных в обучающем наборе могут вызвать коллапс
— теоретический результат, опубликованный на конференции ICLR 2025 Spotlight ( Dohmatob et al., arXiv:2410.04840 ).
Для того чтобы языковая модель перешла от связных текстов о средневековой архитектуре к спискам вымышленных кроликов, достаточно 7-9 поколений рекурсивного обучения ( Шумайлов и др., Nature 2024 ).
От 50 до 74% нового веб-контента уже содержит материалы, сгенерированные искусственным интеллектом ( Graphite , Ahrefs ).
Накопление реальных данных с помощью синтетических данных (вместо их замены) предотвращает коллапс. Но это предполагает контроль над соотношением, что становится невозможным в открытом интернете ( Gerstgrasser et al., arXiv:2404.01413 ).
Ни один крупный обучающий набор данных (FineWeb, RedPajama, C4) не включает систематическую фильтрацию контента, созданного с помощью ИИ ( Penedo et al., NeurIPS 2024 ).
Вопрос уже не в том, реален ли коллапс моделей. Вопрос в том, можем ли мы предотвратить его в масштабах веб-сети.
Эксперимент, который разрушил языковую модель.
В мае 2023 года Илья Шумайлов и его коллеги опубликовали статью на arXiv под пророческим названием: «Проклятие рекурсии». В июле 2024 года статья была опубликована в Nature , самом престижном научном журнале в мире. На сегодняшний день она получила более 500 цитирований . Nature News выпустила специальную статью, предупреждающую о том, что модели ИИ, получающие данные, сгенерированные ИИ, «необратимо» теряют качество.

Визуализация телефонной игры Бартлетта. Сообщение начинается как собор. Двенадцать передач спустя это кролик. Каждое звено сохраняет знакомое и отбрасывает редкое.
Эксперимент простой, почти наивный.
Исследователи взяли OPT-125m , небольшую языковую модель от Meta. Они обучили её на WikiText-2 , корпусе статей Википедии. Первоначальный запрос касался средневековой архитектуры. Поколение 0: модель выдаёт связные тексты об английских соборах, перпендикулярной архитектуре и приходских церквях.
Затем они совершили нечто разрушительное: они обучили вторую модель на
результатах первой. Затем третью — на результатах второй. И так далее.
Пятое поколение : текст начинает смещаться. Темы перетекают одна в другую.
Девятое поколение : модель выдает следующее:
«…чернохвостые зайцы, белохвостые зайцы, синехвостые зайцы…»
Синехвостые кролики. Виды, которых не существует. Средневековая архитектура полностью исчезла. Модель сошлась к абсурдной фиксированной точке — бессмысленному циклу повторения.
Исследователи воспроизвели это явление на трех типах моделей:

Таблица 1: Экспериментальные результаты Шумайлова и др. — Источник: Nature, 2024
Деталь, которая меняет всё: когда исследователи сохранили10% от исходных данныхВ каждом поколении деградация быланезначительный.Без исходных данных уровень перплексии увеличивается на +20–+28 пунктов ( Шумайлов и др., Nature 2024 ).
Это не ошибка. Это теорема.
Как работает механизм коллапса модели: научное объяснение.
Формальное определение однозначно:
Крах модели — это дегенеративный процесс, затрагивающий поколения обученных генеративных моделей, в результате которого генерируемые ими данные загрязняют обучающий набор следующего поколения. Будучи обученными на загрязненных данных, они затем неправильно воспринимают реальность.- Шумайлов и др., Природа 2024.

Поколение 0: средневековая архитектура. Поколение 9: воображаемые синехвостые кролики. Модель не ломается. Она забывает.Проще говоря: когда модель ИИ обучается на выходных данных другой модели ИИ (или самой себя), качество постепенно ухудшается, этот процесс также называется деградацией генеративной модели или самопотребляющим ИИ . Редкие элементы исчезают первыми.
Распространенные элементы становятся чрезмерно представлены. В конечном итоге модель генерирует лишь обедненную, повторяющуюся версию исходного распределения.
Два этапа
Крах разворачивается в два отдельных этапа, и первый из них — самый коварный:

Таблица 2: Две фазы коллапса модели — Источник: Шумайлов и др., Nature 2024
Перечитайте первую строку еще раз. Хвосты исчезают, но центральный пик сохраняется. Именно это делает данное явление опасным. На ранней стадии модель становится «чище». Она генерирует более плавные, усредненные и предсказуемые результаты. Полученные результаты — это те, которые исходная модель сочла бы наиболее вероятными. Тем временем хвосты распределения (редкие случаи, нетипичные стили, языковые меньшинства) исчезают бесследно ( Дохматоб и др., «История хвостов», ICML 2024 ).
Если вы читали мою статью о ложных вознаграждениях ( Статья: Ложные вознаграждения делают ИИ умнее. Никто не знает почему. ), то параллель прямая: модель, кажется, учится (низкая функция потерь, плавные результаты), но при этом незаметно теряет «хвосты» своего распределения. Ранний коллапс модели буквально невозможно обнаружить с помощью стандартных метрик.
Три причины
В статье выделены три источника ошибок, которые накапливаются из поколения в поколение:
Ошибка статистической аппроксимации (основная причина): конечное число выборок приводит к вероятностной потере информации при каждой повторной выборке. Это последовательная репродукция Бартлетта, представленная в математизированном виде.
Ошибка функциональной выразительности (вторичная причина): нейронные сети не обладают идеальной выразительностью. Они не могут представить все распределения. Сеть конечного размера имеет структурные ограничения.
Ошибка функциональной аппроксимации (вторичная причина): индуктивные искажения процедур обучения (в частности, стохастического градиентного спуска) отдают предпочтение одним решениям и игнорируют другие.
В результате процесса образуется цепь Маркова , единственными поглощающими состояниями которой являются дельта-функции. С вероятностью 1 система сходится к одной точке ( Шумайлов и др., Nature 2024
). Математика здесь не прощает ошибок.

Искусственный интеллект Габсбургов. Когда модели обучаются на моделях, генетическое разнообразие рушится. Первые отражения выглядят нормально. У всех дальних отражений одинаковая челюсть.
Метафора, которая всё освещает
Крах модели — это интеллектуальное инбридинг . Когда небольшая популяция размножается только сама с собой, генетическое разнообразие исчезает, накапливаются дефекты, и род деградирует. Модели ИИ, обученные на собственных результатах, делают то же самое — только вместо генов используют идеи.
В научном сообществе действительно используется термин « искусственный интеллект Габсбургов », придуманный исследователем Джатаном Садовски . Эта отсылка к испанским Габсбургам (чье кровосмешение привело к тому, что Карл II, последний представитель династии, не мог даже жевать пищу) столь же жестока, сколь и уместна.
Порог в 0,1%: когда сильный обвал модели меняет правила игры. Хотя статья в журнале Nature заложила основы, именно работа Дохматоба, Фенга, Субрамониана и Кемпе произвела настоящий фурор в научном сообществе. Их работа, посвященная « Краху сильной модели », была принята в качестве « главной темы » на конференции ICLR 2025 , что исторически присуждалось примерно 5% всех представленных работ, и ее результаты вызывают головокружение.
«Даже самая малая доля синтетических данных (например, всего 1 на 1000) может привести к краху модели: всё большие и большие обучающие наборы данных не улучшают производительность». — Дохматоб и др., ICLR 2025
Результаты противоречат интуиции на многих уровнях:
Даже 1 из 1000 (0,1%) синтетических данных может привести к коллапсу режима законов масштабирования.
Коллапс прекращается только тогда, когда синтетическая доля стремится к точному нулю.
Более крупные модели усиливают коллапс , а не наоборот (с важной оговоркой, см. ниже).
Увеличение размера обучающего набора данных не решает проблему.
Третий пункт наиболее противоречит интуиции. В режиме, изученном Дохматобом и др. (нейронные сети, аппроксимированные случайными проекциями регулируемого размера), более крупные модели усиливают коллапс. Однако в статье также отмечается, что за пределами порога интерполяции (который может быть чрезвычайно высоким для очень больших наборов данных) более крупные модели могут ослаблять коллапс, не устраняя его полностью ( Дохматоб и др., ICLR 2025 ).

0,1%. Одна капля из тысячи. Этого достаточно, чтобы загрязнить весь океан. Доказательством тому служит доклад на конференции ICLR 2025: даже следы синтетических данных не позволяют моделям извлечь выгоду из масштаба.ПРЕДУПРЕЖДЕНИЕ : этот порог в 0,1% является теоретическим результатом, полученным в рамках регрессионного анализа с учителем. Это не эмпирический порог, измеренный на производственной модели LLM. Это различие имеет решающее значение. Дохматоб и др. математически демонстрируют, что в их формальной модели любая постоянная ненулевая
доля синтетических данных препятствует использованию моделью законов масштабирования. Прямая экстраполяция на GPT-4 или Llama была бы преждевременной.
Но сигнал очевиден: чем больше синтетических данных загрязняет интернет, тем больше моделей, обученных на этих данных, находятся под угрозой. И проблема усугубляется неприятной реальностью.
Искусственный интеллект: Интернет уже заражен
Цифры плохие:

Таблица 3: Оценка объема контента, созданного с использованием ИИ, в интернете (2025 г.) —
Источники: Graphite , Ahrefs , Originality.ai , Imperva
Следует отметить: все детекторы на основе ИИ имеют существенный процент ложных срабатываний. Единой общепринятой методологии не существует. Реальное число, вероятно, находится где-то между 17% у Originality.ai и 74% у Ahrefs . Даже нижняя оценка вызывает тревогу.
Загрязнение платформой
Это явление носит неоднородный характер. Некоторые платформы затронуты сильнее, чем другие:

Таблица 4: Загрязнение ИИ в зависимости от платформы — Источники: различные
Более половины длинных постов в LinkedIn созданы с помощью ИИ. Amazon Kindle освоил целую категорию электронных книг. На YouTube насчитывается 278 каналов, полностью созданных с помощью ИИ, с общим количеством просмотров 63 миллиарда. NewsGuard обнаружил 2089 фейковых новостных сайтов, полностью созданных с помощью ИИ.

74% нового веб-контента генерируется искусственным интеллектом. А что насчет обучающих наборов данных? Ни один крупный из них не фильтрует синтетические данные. Библиотека тонет в собственных ксерокопиях.А что насчет обучающих наборов данных?
Здесь цикл замыкается. Вот текущее состояние основных наборов данных, используемых для обучения LLM:
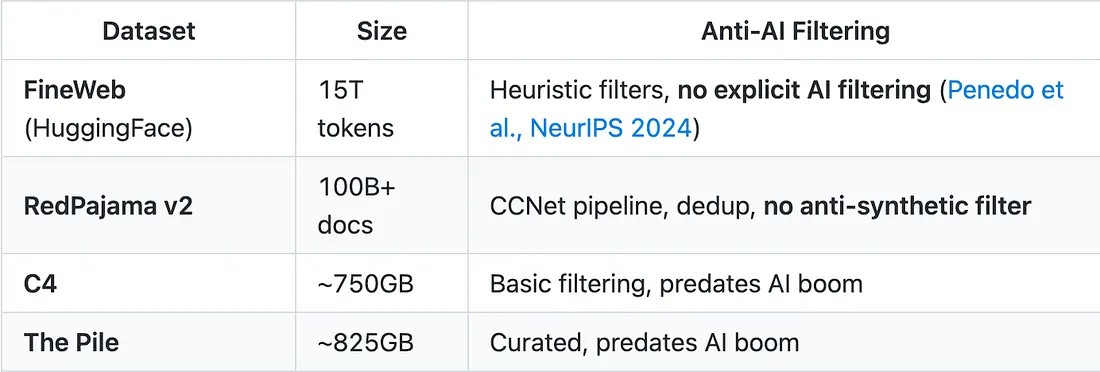
Таблица 5: Фильтрация с использованием методов противодействия ИИ в основных наборах данных
Ни один крупный набор данных не включает систематическую фильтрацию контента, связанного с ИИ ( Penedo et al., NeurIPS 2024 ) . Это самый тревожный пробел во всей экосистеме. Данные до 2022 года (C4, The Pile) относительно чистые, но устаревают. Данные после 2022 года сильно загрязнены, и никто их не фильтрует.
Обратная связь налажена. Возникает самоподдерживающийся цикл
загрязнения обучающих данных для ИИ :
Модели ИИ генерируют контент ->
Контент заполоняет интернет (50-74% новых статей )->
Распространение
Ситуация ухудшается. Приближается « информационный барьер» . По данным Epoch AI , общий объем текстовых данных, созданных людьми, оценивается примерно в 300 триллионов токенов (от 100 до 1000 триллионов). При нынешних темпах переобучения (Llama 3 использует примерно в 10 раз больше токенов, чем Chinchilla, по данным Meta, 2024 ), истощение прогнозируется примерно к 2027 году .
Мы движемся к арифметическому тупику: дефицит обучающих данных приводит к краху качества обучающих данных . Модельм нужно больше данных, интернет в основном производит синтетические данные, а синтетические данные приводят к краху. Произведите расчеты.
Проблема распределения по хвостам распределения: кто исчезнет первым?
Проблема краха модели — это не просто техническая проблема. Это проблема справедливости.Первое, что устраняет коллапс, — это « хвосты» распределения : редкие случаи, выбросы, меньшинства. В языке это недостаточно представленные языки, диалекты, нетипичные стили письма, маргинальные культурные взгляды.В работе Го и др. (Результаты NAACL 2024) это было измерено эмпирически. Они оценили лингвистическое разнообразие результатов, генерируемых рекурсивно обученными LLM-моделями, на трех уровнях: лексическом,
синтаксическом и семантическом. Результат: последовательное снижение разнообразия на всех трех уровнях, особенно выраженное для творческих задач .

Хвосты исчезают первыми. Редкие языки. Нетипичные стили. Мнения меньшинств. Схлопывание модели оптимизирует результат по среднему значению и исключает все остальное.Это интеллектуальный эквивалент сельскохозяйственной монокультуры. Промышленное сельское хозяйство оптимизирует урожайность до среднего уровня: оно уничтожает редкие сорта и создает хрупкую монокультуру. Крах модели делает то же самое со знаниями: он оптимизирует урожайность до среднего уровня, уничтожает редкие сорта и создает неустойчивую интеллектуальную монокультуру.Чтобы в полной мере понять масштаб проблемы, нам необходимо вернуться к концепции расстройства аутофагии (MAD), предложенной Алемохаммадом и др. (ICLR 2024) . Этот термин является прямой аналогией с бычьей губчатой энцефалопатией (коровьим бешенством), при которой организм дегенерирует, потребляя переработанные остатки себе подобных.
Исследователи из Университета Райса выделили три типа аутофагических петель :
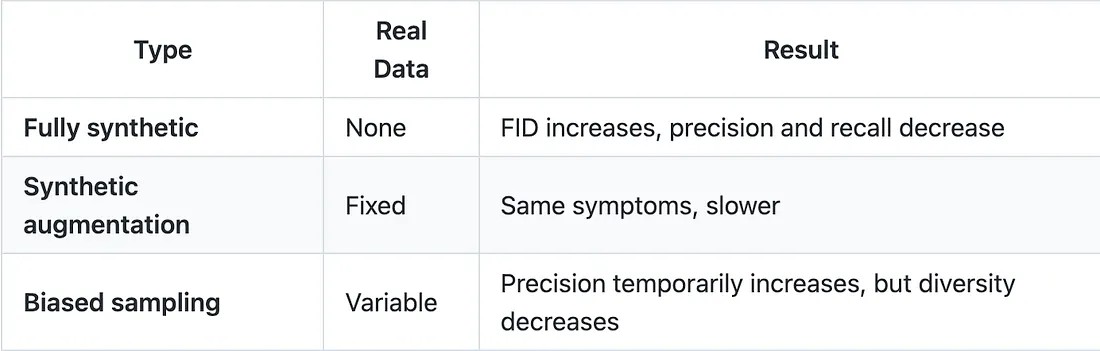
Таблица 6: Типы аутофагических петель — Источник: Alemohammad et al., ICLR 2024
Третий тип — самый пагубный: точность временно повышается. Модель
«улучшается», но только в типичных случаях. Разнообразие падает. Это ранний пример коллапса модели, невидимый для стандартных метрик.
«Без достаточного количества свежих реальных данных в каждом поколении будущие генеративные модели обречены на постепенное снижение качества (точности) или разнообразия (полноты)». — Алемохаммад и др., ICLR 2024
Если обучающие данные искажены, даже лучшие инструменты для проверки интерпретируемости, такие как PaTH ( статья: Ваша модель LLM не может отследить выключатель света. Математический трюк 1958 года это исправит ), будут работать с искаженной моделью. Вы не сможете правильно диагностировать пациента с помощью сканера, откалиброванного на ложных изображениях.
Контраргумент: Когда синтетические данные работают Интеллектуальная строгость требует представления обеих сторон. И контраргумент вполне убедителен.
Герстграссер и др.: Накопление как средство лечения
Наиболее убедительный вывод во всей литературе, посвященной коллапсу моделей, исходит не от катастрофистов. Он исходит от Герстграссера, Шаффера и др. (2024) , которые теоретически и эмпирически продемонстрировали, что коллапс является артефактом стратегии замены , а не неизбежностью.

Таблица 7: Замещение против накопления — Источник: Gerstgrasser et al., arXiv:2404.01413
Результат подтверждается для трансформеров , VAE , диффузионных моделей и даже молекулярных конформаций . Доказательства убедительны. Если сохранить исходные данные и добавить синтетические данные ( вместо замены), ошибка модели останется ограниченной. Коллапса не происходит.
Шаффер и др.: 8 определений, слишком много путаницы
В 2025 году Шаффер и др. опубликовали проницательную аналитическую статью: «Крах модели означает не то, что вы думаете». Их вывод: в литературе используется как минимум 8 различных определений «краха модели», что делает любые обобщения рискованными.
Их главный аргумент: катастрофические сценарии основаны на нереалистичных предположениях, прежде всего на полной замене данных в каждом поколении. Ни одна серьезная лаборатория так не поступает. В реальных системах обучения данные смешиваются, фильтруются и обрабатываются.
Стоит отметить, что Шаффер является соавтором работы Герстграссера и др.
, поэтому это согласуется с их предыдущими исследованиями. По сути, они говорят: «Да, коллапс реален при определенных условиях. Нет, эти условия не описывают то, что на самом деле делают крупные лаборатории».
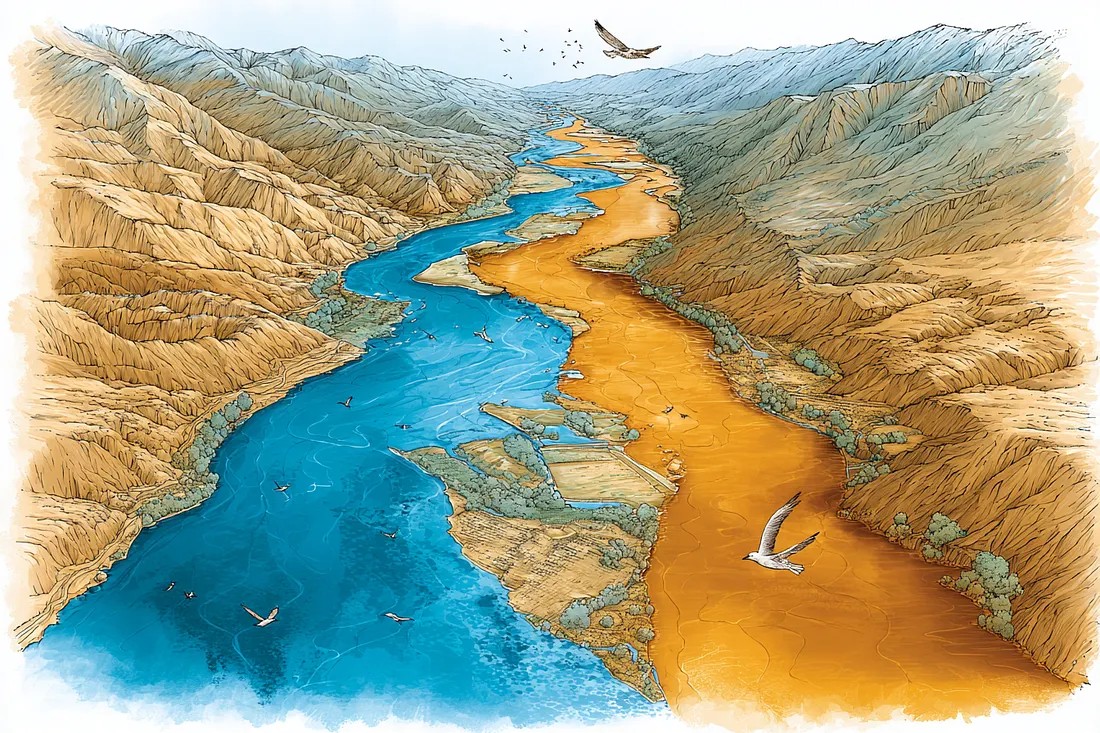
Накопление (слева) против замещения (справа). Герстграссер и др. доказали это: добавление синтетических данных к реальным данным не приводит к коллапсу. Замена реальных данных синтетическими приводит к гибели реки.Пример с числом Фи: контрпример, добавляющий нюансы.
Модель Phi-4 от Microsoft (14 миллиардов параметров) обучена на 50 типах синтетических наборов данных , содержащих приблизительно 400 миллиардов синтетических токенов , и набрала 91,8% баллов на тесте AMC (American Mathematics Competition) в ноябре 2024 года ( Abdin et al., arXiv:2412.08905 ). Это живое доказательство того, что высококачественные, тщательно отобранные синтетические данные работают .
Но — и это очень важное «но» — подозрения в переобучении эталонных показателей сохраняются. И что еще важнее, это не тот же сценарий, что и бесконтрольное загрязнение интернета некачественными материалами, созданными ИИ. Phi — это упражнение в тщательной обработке данных.
Интернет — это джунгли.
Почему контраргумент недостаточен
Моё понимание обеих позиций: Герстграссер прав в теории. Накопление предотвращает коллапс. Но его решение предполагает контроль соотношения реальных и синтетических данных , что становится невозможным в масштабах открытой сети.
Когда 74% новых веб-страниц содержат контент, созданный с помощью ИИ, когда ни один крупный набор данных не фильтрует синтетические данные, когда точность детекторов ИИ в реальных условиях ограничена 65–90% ( Dugan et al., “RAID”, ACL 2024 ), стратегия чистого накопления становится роскошью, которую могут позволить себе только самые хорошо финансируемые лаборатории.
Проблема не в том, что коллапс неизбежен в лабораторных условиях. Проблема в том, что он вероятен в реальных условиях.
Решения для предотвращения сбоя модели
Обнаружение и нанесение водяных знаков

Таблица 8: Состояние решений для обнаружения — Источники: Google SynthID , Content Authenticity Initiative
В рамках теста RAID ( ACL 2024) детекторы были протестированы на более чем 6 миллионах текстов , 11 LLM и 11 доменах . Вердикт: детекторы достигают высокой точности только при одинаково высоком уровне ложных срабатываний . Простые атаки с использованием состязательных методов
(синонимы, перефразирование) снижают точность некоторых детекторов
более чем на 36 пунктов , в то время как другие к ним нечувствительны. Эффекты непредсказуемы и зависят от детектора. Короче говоря: мы не знаем, как надежно фильтровать.
Регулирование
Закон ЕС об искусственном интеллекте (статья 50) потребует машиночитаемой маркировки всего контента, созданного с помощью ИИ, начиная с августа 2026 года . Агентство национальной безопасности США и Управление информационной безопасности рекомендуют использовать C2PA для обеспечения целостности мультимедийного контента. Однако вопрос о применении этих мер остается открытым.
Стратегии работы лаборатории
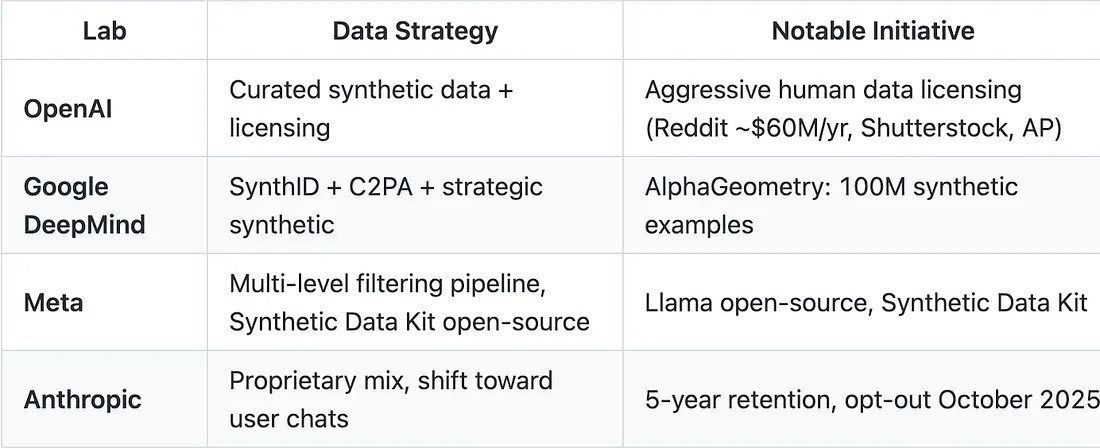
Таблица 9: Подходы ведущих лабораторий — Источники: Источник: Meta Synthetic Data Kit
Чего не хватает
Центральный парадокс остается неразрешенным:
Для масштабирования нам необходимы синтетические данные, но они приводят к коллапсу.
В литературе предлагается пять рычагов воздействия:
Накопление , а не восполнение ( Герстграссер и др. )
Проверка с помощью оракула/верификатора ( Фенг и др., arXiv:2510.16657 )
Разнообразие источников (многомодельный подход)
Сохранение реальных данных как якоря
Агрессивная фильтрация низкокачественных изображений
Ни одна из них не внедряется систематически. Ни одна не работает в масштабах веб-приложений. Система давно не работает. Крах модели лишь выявил эту трещину.
Моё мнение
Коллапс модели — это реальность. Доказано. Опубликовано в Nature, ICLR, ICML, NeurIPS, NAACL. Это не паникерство; это математически доказанное явление, подкрепленное убедительными экспериментальными доказательствами.
Но я отвергаю катастрофическую интерпретацию. Коллапс не неизбежен. Герстграссер и Шаффер правы: с помощью тщательно отобранных данных, стратегии накопления и строгой фильтрации лаборатории могут избежать наихудшего сценария. Phi-4 это демонстрирует.

Трагедия общих ресурсов, применительно к данным. Каждый выбрасывает в общедоступную сеть синтетический контент. Никто не отвечает за его фильтрацию. Источник уже испорчен.Проблема не техническая. Она структурная . Это проблема общих ресурсов, трагедия общих ресурсов, применительно к данным. У каждого участника есть стимул создавать синтетический контент (он бесплатный, он масштабируемый). Но коллективный эффект загрязняет общий ресурс (интернет). И никто не несет ответственности за фильтрацию.
Именно это происходит с океанами, грунтовыми водами, воздухом. Мы знаем механизм. Мы знаем решения. И мы внедряем их слишком поздно, потому что издержки носят коллективный характер, а выгода – индивидуальный.
Мой прогноз: ведущие лаборатории (OpenAI, Google, Anthropic, Meta) избегут краха благодаря своим собственным наборам данных, командам по их обработке и приоритетному доступу к высококачественным данным, полученным от людей. Первыми пострадают модели с открытым исходным кодом, небольшие лаборатории и стартапы, зависящие от открытого интернета.
Крах модели не убьет ИИ. Он создаст раскол между теми, кто имеет доступ к чистым данным, и теми, кто его не имеет. Разделительной линией станет качество данных для ИИ .
Ограничения и открытые вопросы
Вот что эта статья не доказывает:
Пороговое значение 0,1% является теоретическим результатом в регрессионном анализе с учителем. Его прямая применимость к производственным моделям LLM не продемонстрирована.
Показатели загрязнения интернета (50–74%) основаны на данных детекторов искусственного интеллекта, надежность которых оспаривается. Реальное число может значительно отличаться.
Не существует ни одного публично задокументированного случая полного краха модели в крупной лаборатории. Отрасль действует превентивно , а не реактивно.
В экспериментах Шумайлова используются относительно небольшие модели (OPT-125m). Поведение моделей с более чем 175 миллиардами параметров может отличаться.
Масштабы этого явления в мультимодальных моделях (текст +
изображение + видео) до сих пор в значительной степени не изучены.
В статье Шаффера и соавторов поднимается важный вопрос: восемь различных определений «коллапса модели», встречающихся в литературе, затрудняют сравнения.
Что это значит для вашей стратегии в области ИИ?
Если вы исследователь в области машинного обучения
Инвестируйте в отслеживание происхождения данных . Документируйте происхождение ваших обучающих данных. Используйте стандарты отслеживания происхождения контента, такие как метаданные C2PA, если они доступны.
В качестве базовых показателей отдавайте предпочтение наборам данных, собранным до 2022 года.
Проверяйте не только точность, но и разнообразие ваших моделей. Стандартные метрики маскируют ранний сбой в работе модели.
При упоминании коллапса модели следует указывать точную теоретическую основу: теория Шумайлова (рекурсивная), теория Дохматоба (сильная), теория Алемахаммада (MAD) описывают не совсем одно и то же явление.
Если вы разрабатываете продукты на основе искусственного интеллекта
Проведите аудит ваших наборов данных на предмет наличия синтетического контента. То, что вы не измеряете, может привести к катастрофе.
Инвестируйте в высококачественные данные о человеческом факторе, даже если это дороже. Это конкурентное преимущество, которое будет только расти.
В процессах обучения отдавайте предпочтение накоплению, а не замещению.
Не стоит полагаться на детекторы на основе ИИ как на единственную линию защиты. Их реальная точность составляет 65–90% , а не заявленные 98% ( RAID, ACL 2024 ).
Если вы принимаете решения / являетесь инвестором
«Информационный ров» — это новый «вычислительный ров». Премия за данные о человеческом факторе реальна: компании, имеющие доступ к чистым и разнообразным данным о людях, обладают структурным преимуществом.
Крах модели — это системный риск для моделей, зависящих от открытого интернета. Оцените степень подверженности этому риску в своем портфеле.
Закон ЕС об искусственном интеллекте (статья 50) , вступающий в силу в августе 2026 года, создаст новые обязательства по обеспечению прозрачности. Планируйте заранее.
Часто задаваемые вопросы: Объяснение механизма свертывания модели
Влияет ли сбой модели на существующие модели (GPT-4, Claude, Gemini)?
Нет общедоступных доказательств. Крупные лаборатории тщательно отбирают данные, используют собственные источники и располагают ресурсами для фильтрации. Но они не публикуют точный состав своих наборов данных. Мы не знаем того, чего не знаем.
Действительно ли 0,1% данных, полученных с помощью ИИ, достаточно, чтобы сломать модель?
Это теоретический результат ( Дохматоб и др., ICLR 2025 Spotlight ), полученный в рамках контролируемой регрессии. Это не эмпирический порог, измеренный на модели LLM. Он показывает, что даже бесконечно малые следы синтетических данных препятствуют использованию моделью законов масштабирования, что является сильным сигналом, но не прямым измерением, применимым к GPT-5.
Всегда ли синтетические данные вредны?
Нет. Высококачественные синтетические данные, подобранные специально для конкретной задачи, работают. AlphaGeometry от Google успешно использует 100 миллионов синтетических примеров. Phi-4 от Microsoft использует около 400 миллиардов синтетических токенов, стратегически интегрированных в корпус токенов объемом 9,8 ТБ ( Abdin et al., arXiv:2412.08905 ). Ключевым моментом является качество подбора данных и контроль процесса . Некачественные результаты ИИ в интернете несравнимы с результатами тщательно подобранного синтеза.
Что конкретно я могу сделать, чтобы защитить себя?
Отдавайте предпочтение наборам данных, собранным до 2022 года, в качестве базовых показателей. Документируйте происхождение данных. Проверяйте разнообразие (а не только точность). Накапливайте данные, а не заменяйте
их. И инвестируйте в данные, полученные от людей. Это новая нефть, и запасы иссякают ( Epoch AI ).
Может ли коллапс модели самокорректироваться?
Теоретически, если доля синтетического контента в интернете стабилизируется (за счет регулирования или насыщения) и улучшатся методы фильтрации, то да. На практике же мы движемся в этом направлении. Объем контента, созданного с помощью ИИ, растет экспоненциально, детекторы стагнируют, и никакой рыночный механизм не стимулирует сокращение производства синтетического контента.
Заключение: Уроборос и мрамор
Вся эта история содержит мета-парадокс.
Величайший прогресс в генерации языка в истории человечества заключается в уничтожении самого исходного материала, необходимого для этого. Чем лучше становятся модели, чем больше контента они генерируют, чем больше загрязняется интернет, тем хуже будут будущие модели. Уроборос — змей, пожирающий собственный хвост, — это уже не метафора. Это механизм.

Уроборос. Чем лучше становятся модели, тем больше контента они генерируют, тем больше загрязняется интернет, тем хуже становится следующее поколение. Змей пожирает собственный хвост.Микеланджело говорил, что статуя уже была внутри мрамора. Все, что нужно было сделать, это удалить излишки, чтобы ее обнажить. «Обрушение модели» делает обратное: с каждым поколением удаляется кусочек мрамора, немного деталей, немного нюансов — пока не останется ничего, кроме гладкой, шаблонной, безликой формы.
Оглядываясь назад, можно сказать, что признаки были налицо. Мы создали системы, которые оптимизируются в невидимые тупики: модели, которые обманывают систему вознаграждений ( Статья: Ложные вознаграждения делают ИИ умнее. Никто не знает почему. ), модели, внутреннюю логику
которых мы наконец-то можем прочитать ( Статья: Ваша LLM не может отследить выключатель света. Математический трюк 1958 года решает эту проблему. ), модели, которые уничтожают необходимые им данные. Общая нить: неограниченная оптимизация сходится к решениям, которые выглядят хорошо, но на самом деле пусты.
Одно можно сказать наверняка: пути назад нет. Интернет заражен. Данные, полученные от людей, заканчиваются. Искусственный интеллект пришел и останется с нами навсегда.
Вопрос уже не в том, реален ли коллапс моделей. Вопрос в том, что мы строим сейчас, с какими данными, какими гарантиями, какими ограничениями, чтобы предотвратить превращение следующего поколения моделей в обедненную версию предыдущего.
Вопрос в том: кто станет хранителем чистых данных и какой ценой?
✦ Делано Пирард ✦
Исследователь и инженер в области искусственного интеллекта
🌐 delanoe-pirard.com
💻 github.com/Aedelon
💼 linkedin.com/in/delanoe-pirard
𝕏 x.com/0xAedelon
Источники
Академические исследования (Уровень 1: Природа / Лучшие конференции)
Шумайлов, И. и др. (2024). «Модели ИИ рушатся при обучении на рекурсивно сгенерированных данных». Nature , 631, 755–759. DOI:10.1038/s41586–024–07566-y
Дохматоб, Э., Фенг, И., Субрамониан, А. и Кемпе, Дж. (2024). «Коллапс сильной модели». ICLR 2025 Spotlight . arXiv:2410.04840
Дохматоб, Э. и др. (2024). «История о решках». ICML 2024. arXiv :2402.07043
Алемохаммад, С. и др. (2024). «Самопотребляющие генеративные модели становятся безумными». ICLR 2024. arXiv :2307.01850
Го, Ю. и др. (2024). «Загадочное сокращение языкового разнообразия».
Результаты конференции NAACL 2024. arXiv :2311.09807
Дуган и др. (2024). «RAID: надежная оценка детекторов текста, генерируемых машинным способом». ACL 2024. arXiv :2405.07940
Пенедо и др. (2024). «Наборы данных FineWeb». НейрИПС 2024 . arXiv:2406.17557
Академические исследования (Уровень 2: Высокорейтинговый arXiv)
Герстграссер, М. и др. (2024). «Неизбежен ли коллапс модели?»
arXiv:2404.01413
Шаффер, Р. и др. (2025). «Позиция: коллапс модели означает не то, что вы думаете». arXiv:2503.03150
Фэн и др. (2025). «Избежание коллапса модели посредством проверки синтетических данных». arXiv:2510.16657
Источники информации в отрасли и СМИ
Graphite (октябрь 2025 г.). «Сейчас искусственный интеллект создает больше статей, чем люди».
Ahrefs (2025). «Какой процент нового контента генерируется искусственным интеллектом?»
Originality.ai (2025). «Контент, созданный с помощью ИИ, в результатах поиска Google».
Imperva (2025). «Отчет о вредоносных ботах 2025».
Kapwing (декабрь 2025 г.). «Отчет о низкокачественных видеороликах, созданных с помощью ИИ: глобальный рост числа таких видео».
NewsGuard (2025). «Центр отслеживания ИИ». 2089 сайтов с фейковыми новостями, созданных с помощью ИИ.
Epoch AI . «Не закончится ли у нас количество данных?»
Google DeepMind — SynthID . Технология водяных знаков с открытым исходным кодом.
Инициатива по обеспечению подлинности контента (2025). 5000 членов
C2PA.
Статья 50 Закона ЕС об искусственном интеллекте . Обязательная маркировка с августа 2026 года.
АНБ/CISA (январь 2025 г.). Рекомендация по аккредитации.
Meta — Набор синтетических данных (2025). С открытым исходным кодом.
Ши, В. и др. (2024). «Выявление данных предварительного обучения в больших языковых моделях». arXiv:2410.08044
Судебная экспертиза в области ИИ (декабрь 2025 г.). Расследование использования ИИ-активов в TikTok.
Yahoo News (2025). «77% успеха в категории „Успех“ на Amazon Kindle
генерируется искусственным интеллектом».
Дубей, А. и др. (2024). «Стадо моделей Llama 3». Meta.arXiv :2407.21783
Абдин, М. и др. (2024). «Технический отчет по Phi-4». Microsoft Research . arXiv:2412.08905
